Implementing Code Review Feedback: To Squash or Not to Squash?
Giving and receiving feedback is an integral part of code reviews. While feedback helps to reduce the number of bugs and should result in more maintainable code, the process doesn’t come without challenges. Receiving criticism for your work can be difficult and cause tension in the team. In this blog post, however, we want to take a look at a more technical aspect of dealing with feedback. We want to figure out the best way to implement change requests into the code.
There are two options if you are asked to change the code of your merge request. Both approaches come with their advantages and disadvantages.
Appending new commits
Appending new commits is super easy and fast. By creating one commit per change request you help the reviewer understand how you addressed their feedback. The downside of this approach is that you end up with a somewhat unclean git history.
A clean git history is not just a matter of having a nicer git log output. If your project grows and gets more complex over time, pinpointing what causes a bug gets more difficult. You might want to use git bisect to figure out which change broke the code (see git user manual or git bisect for more information). This process only works if you can tell for each commit whether it contains the buggy behavior or not. Commits containing broken code can therefore be quite annoying. You might end up with the wrong result or you have to skip commits.
One way of avoiding this problem is to squash your commits during a merge. This works great for small merge requests with only one initial commit. When your changes become larger, you might want to group them into small logical commits. This does not only improve the precision of your git bisect result, but also speeds up code reviews. Squashing them during a merge would be counterproductive as everything ends up in a single commit again.
Modifying existing commits
You can avoid most of the disadvantages mentioned above by implementing the feedback in the original commits. This approach requires a bit more time and knowledge about git. If you are new to git, the easiest way of editing an existing commit is not always obvious. If your merge request contains only one commit, you can just substitute git commit -m "..." with git commit --amend and you are done. When fixing the second to last commit or any older commit, things get a bit more complicated though. One way is to use an interactive rebase (git rebase -i base_branch) and mark the commits you want to edit. You can find a nice tutorial on how to do this here or take a look at the git user manual. While this method is very powerful and allows you to modify your git history in all kinds of ways, it is not the fastest method of fixing your commits.
Combining both approaches: fixup commits
There is a lesser-known feature in git which allows you to combine both approaches. You create new commits for your changes but still end up with a clean git history. I am talking about fixup commits. These are commits with a special commit message that instructs git rebase to merge the changes back into the respective original commits. Don’t be surprised if you have never heard of them. The git manual doesn’t mention them and the remaining documentation doesn’t necessarily do a good job in explaining this feature either. Let’s change that and take a look at how to use them.
In this example we try to fix the following git history (git log --oneline):
29a0f49 (HEAD -> feature-branch) good commit
54a0517 broken commit
00eecd3 (master) initial commit
Using our ability to predict the future, we already named the commit that needs to be fixed as “broken commit”. The first step is to modify the code and stage the changes as usual (e.g. git add -u -p). When committing the changes, we do not provide a commit message but instead, instruct git to create a fixup commit using git commit --fixup 54a0517. The newly created git commit looks like this:
c1e7149 (HEAD -> feature-branch) fixup! broken commit
29a0f49 good commit
54a0517 broken commit
00eecd3 (master) initial commit
To get a clean git history we need to rebase the changes back into their respective original commits by executing git rebase -i --autosquash. Git will now display what will happen during the rebase. Unless you want to manually change other parts of the history (e.g. a commit message), you can just close the editor. When taking a look at git log --oneline, you will notice that there is no trace of the fixup commit anymore:
8f15489 (HEAD -> feature-branch) good commit
079dc70 broken commit
00eecd3 (master) initial commit
The history looks almost identical to the initial one, only the hashes changed due to the rebase. If you want to see how it looks in practice, take a look at this screencast:
This is a very basic example to showcase how fixup commits work. In practice, you might have multiple fixup commits, maybe even targeting the same original commit.
Are fixup commits the solution?
Fixup commits are a great way of integrating feedback, but they also come with their limitations. If your commits depend on each other or edit the same area of code, git may not be able to automatically rebase your fixes into the existing commits. You will end up stepping through the git history using interactive rebases again. Speaking from my own experience though, I can nearly always use fixup commits. This requires small atomic commits and you may want to order certain actions, like moving a code block, in a way that allows easier rebasing.
Another possible pitfall is creating broken commits without noticing it. If you rebase a change into the wrong commit, the rebase might succeed but the resulting code might be invalid, e.g. you call a function defined in a later commit. Luckily git offers a solution to this problem as well. We can tell git rebase to execute a command on each commit and stop on a non-zero exit code. This allows us to compile the code or run tests. If you want to run make test on each commit, you can do so using git rebase --exec "make test" base_branch. You can also combine both steps and run git rebase -i --autosquash --exec "make test" base_branch to notice any issues immediately. As a side note, the same is possible with git bisect. You can completely automate the bisect process as long as you can write a script/program to detect the presence of the bug.
There is still a minor annoyance when adopting the fixup workflow. Looking up the hash or reference of the commit to provide to git commit --fixup is somewhat cumbersome. There are various wrappers available that try to solve this type of issue though, e.g. git-fixup, git-autofixup, or git-absorb.
Fixup commits and MergeBoard
When using fixup commits you might forget to rebase the fixes before pushing them. Maybe you are even doing it intentionally. Having your fixes in separate commits makes it easier for a reviewer to understand how you implemented their feedback. In both cases, you want to rebase them before merging. Otherwise, you end up with fixup commits in your target branch.
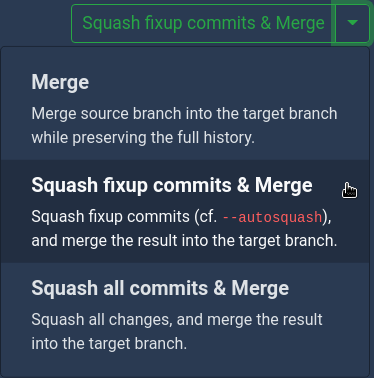
While working on MergeBoard, our code review software, we also failed to pay attention a few times - with the effect that fixup commits ended up in our main branch. Since we are also using MergeBoard to review our MergeBoard changes, we were able to fix this issue. We made MergeBoard aware of fixup commits and added a new merge mode. MergeBoard will now by default try to rebase any existing fixup commits when merging. If the rebase fails, the merge is aborted. This feature has already been rolled out to all customers with the last update. You are still able to override this behavior:
We hope this article helps you implement code review feedback more effectively in the future. If you found this blog entry informative and want to stay tuned, subscribe to our RSS feed or follow us on LinkedIn.